2024
 R^2-Tuning: Efficient Image-to-Video Transfer Learning for Video Temporal GroundingarXiv:2404.00801
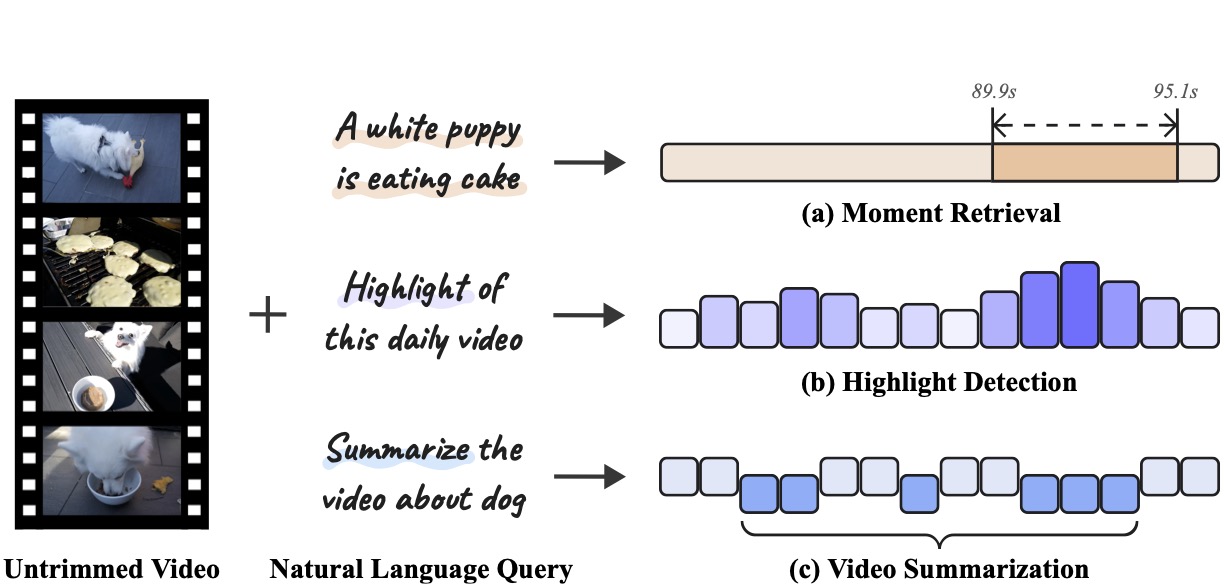
R^2-Tuning: Efficient Image-to-Video Transfer Learning for Video Temporal GroundingarXiv:2404.00801Video temporal grounding (VTG) is a fine-grained video understanding problem that aims to ground relevant clips in untrimmed videos given natural language queries. Most existing VTG models are built upon frame-wise final-layer CLIP features, aided by additional temporal backbones (e.g., SlowFast) with sophisticated temporal reasoning mechanisms. In this work, we claim that CLIP itself already shows great potential for fine-grained spatial-temporal modeling, as each layer offers distinct yet useful information under different granularity levels. Motivated by this, we propose Reversed Recurrent Tuning (R^2-Tuning), a parameter- and memory-efficient transfer learning framework for video temporal grounding. Our method learns a lightweight R^2 Block containing only 1.5% of the total parameters to perform progressive spatial-temporal modeling. Starting from the last layer of CLIP, R^2 Block recurrently aggregates spatial features from earlier layers, then refines temporal correlation conditioning on the given query, resulting in a coarse-to-fine scheme. R^2-Tuning achieves state-of-the-art performance across three VTG tasks (i.e., moment retrieval, highlight detection, and video summarization) on six public benchmarks (i.e., QVHighlights, Charades-STA, Ego4D-NLQ, TACoS, YouTube Highlights, and TVSum) even without the additional backbone, demonstrating the significance and effectiveness of the proposed scheme.
 Learning to Aggregate Multi-Scale Context for Instance Segmentation in Remote Sensing ImagesIEEE Transactions on Neural Networks and Learning Systems (TNNLS)
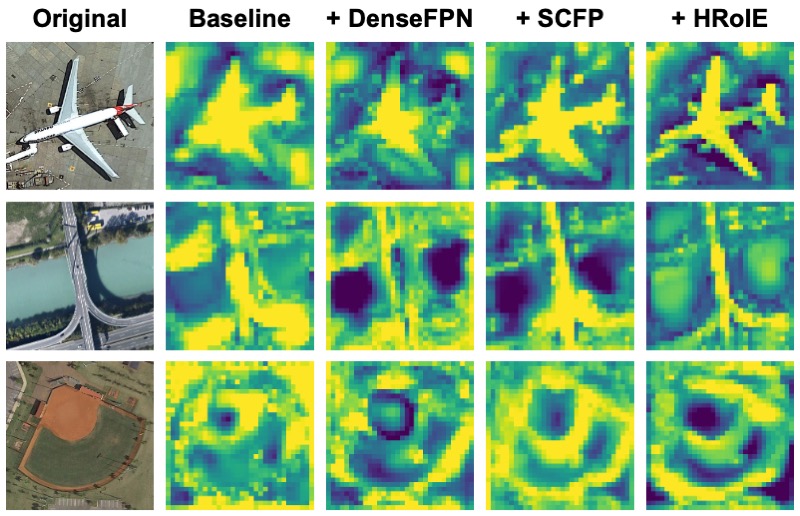
Learning to Aggregate Multi-Scale Context for Instance Segmentation in Remote Sensing ImagesIEEE Transactions on Neural Networks and Learning Systems (TNNLS)The task of instance segmentation in remote sensing images, aiming at performing per-pixel labeling of objects at instance level, is of great importance for various civil applications. Despite previous successes, most existing instance segmentation methods designed for natural images encounter sharp performance degradations when they are directly applied to top-view remote sensing images. Through careful analysis, we observe that the challenges mainly come from the lack of discriminative object features due to severe scale variations, low contrasts, and clustered distributions. In order to address these problems, a novel context aggregation network (CATNet) is proposed to improve the feature extraction process. The proposed model exploits three lightweight plug-and-play modules, namely dense feature pyramid network (DenseFPN), spatial context pyramid (SCP), and hierarchical region of interest extractor (HRoIE), to aggregate global visual context at feature, spatial, and instance domains, respectively. DenseFPN is a multi-scale feature propagation module that establishes more flexible information flows by adopting inter-level residual connections, cross-level dense connections, and feature re-weighting strategy. Leveraging the attention mechanism, SCP further augments the features by aggregating global spatial context into local regions. For each instance, HRoIE adaptively generates RoI features for different downstream tasks. Extensive evaluations of the proposed scheme on iSAID, DIOR, NWPU VHR-10, and HRSID datasets demonstrate that the proposed approach outperforms state-of-the-arts under similar computational costs.
2023
 Timestamps as Prompts for Geography-Aware Location RecommendationIn Proceedings of the ACM International Conference on Information and Knowledge Management (CIKM 2023)
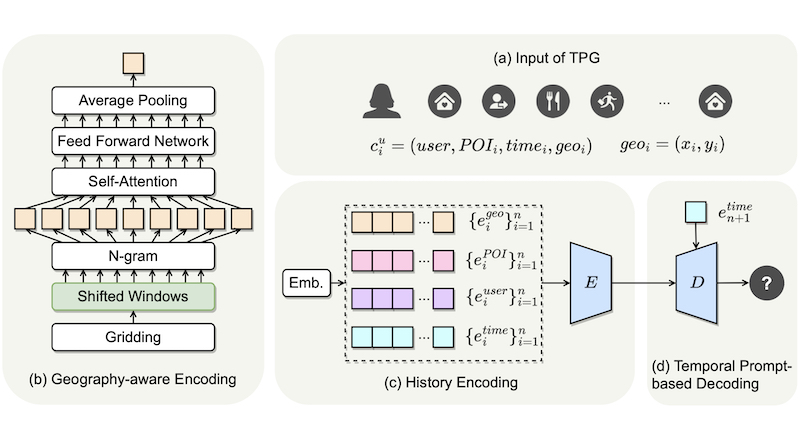
Timestamps as Prompts for Geography-Aware Location RecommendationIn Proceedings of the ACM International Conference on Information and Knowledge Management (CIKM 2023)Location recommendation plays a vital role in improving users’ travel experience. The timestamp of the POI to be predicted is of great significance, since a user will go to different places at different times. However, most existing methods either do not use this kind of temporal information, or just implicitly fuse it with other contextual information. In this paper, we revisit the problem of location recommendation and point out that explicitly modeling temporal information is a great help when the model needs to predict not only the next location but also further locations. In addition, state-of-the-art methods do not make effective use of geographic information and suffer from the hard boundary problem when encoding geographic information by gridding. To this end, a Temporal Prompt-based and Geography-aware (TPG) framework is proposed. The temporal prompt is firstly designed to incorporate temporal information of any further check-in. A shifted window mechanism is then devised to augment geographic data for addressing the hard boundary problem. Via extensive comparisons with existing methods and ablation studies on five real-world datasets, we demonstrate the effectiveness and superiority of the proposed method under various settings. Most importantly, our proposed model has the superior ability of interval prediction. In particular, the model can predict the location that a user wants to go to at a certain time while the most recent check-in behavioral data is masked, or it can predict specific future check-in (not just the next one) at a given timestamp.
 End-to-End Personalized Next Location Recommendation via Contrastive User Preference ModelingarXiv:2303.12507
End-to-End Personalized Next Location Recommendation via Contrastive User Preference ModelingarXiv:2303.12507Predicting the next location is a highly valuable and common need in many location-based services such as destination prediction and route planning. The goal of next location recommendation is to predict the next point-of-interest a user might go to based on the user’s historical trajectory. Most existing models learn mobility patterns merely from users’ historical check-in sequences while overlooking the significance of user preference modeling. In this work, a novel Point-of-Interest Transformer (POIFormer) with contrastive user preference modeling is developed for end-to-end next location recommendation. This model consists of three major modules: history encoder, query generator, and preference decoder. History encoder is designed to model mobility patterns from historical check-in sequences, while query generator explicitly learns user preferences to generate user-specific intention queries. Finally, preference decoder combines the intention queries and historical information to predict the user’s next location. Extensive comparisons with representative schemes and ablation studies on four real-world datasets demonstrate the effectiveness and superiority of the proposed scheme under various settings.
2022
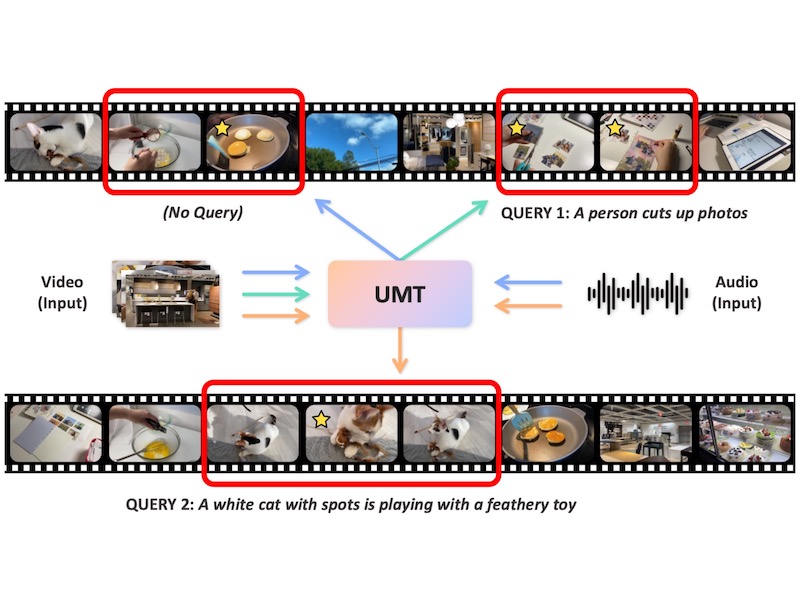 UMT: Unified Multi-modal Transformers for Joint Video Moment Retrieval and Highlight DetectionIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022)
UMT: Unified Multi-modal Transformers for Joint Video Moment Retrieval and Highlight DetectionIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022)Finding relevant moments and highlights in videos according to natural language queries is a natural and highly valuable common need in the current video content explosion era. Nevertheless, jointly conducting moment retrieval and highlight detection is an emerging research topic, even though its component problems and some related tasks have already been studied for a while. In this paper, we present the first unified framework, named Unified Multi-modal Transformers (UMT), capable of realizing such joint optimization while can also be easily degenerated for solving individual problems. As far as we are aware, this is the first scheme to integrate multi-modal (visual-audio) learning for either joint optimization or the individual moment retrieval task, and tackles moment retrieval as a keypoint detection problem using a novel query generator and query decoder. Extensive comparisons with existing methods and ablation studies on QVHighlights, Charades-STA, YouTube Highlights, and TVSum datasets demonstrate the effectiveness, superiority, and flexibility of the proposed method under various settings.
2020
 ConsNet: Learning Consistency Graph for Zero-Shot Human-Object Interaction DetectionIn Proceedings of the ACM International Conference on Multimedia (MM 2020)
ConsNet: Learning Consistency Graph for Zero-Shot Human-Object Interaction DetectionIn Proceedings of the ACM International Conference on Multimedia (MM 2020)We consider the problem of Human-Object Interaction (HOI) Detection, which aims to locate and recognize HOI instances in the form of <human, action, object> in images. Most existing works treat HOIs as individual interaction categories, thus can not handle the problem of long-tail distribution and polysemy of action labels. We argue that multi-level consistencies among objects, actions and interactions are strong cues for generating semantic representations of rare or previously unseen HOIs. Leveraging the compositional and relational peculiarities of HOI labels, we propose ConsNet, a knowledge-aware framework that explicitly encodes the relations among objects, actions and interactions into an undirected graph called consistency graph, and exploits Graph Attention Networks (GATs) to propagate knowledge among HOI categories as well as their constituents. Our model takes visual features of candidate human-object pairs and word embeddings of HOI labels as inputs, maps them into visual-semantic joint embedding space and obtains detection results by measuring their similarities. We extensively evaluate our model on the challenging V-COCO and HICO-DET datasets, and results validate that our approach outperforms state-of-the-arts under both fully-supervised and zero-shot settings.